
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 자바스크립트forinforof차이
- vue환경세팅
- Android
- 스택과큐의차이점
- 장고
- R데이터분석
- vue환경설정
- 자바스크립트날짜
- 큐개념
- 안드로이드
- 자바스크립트날짜get
- 스택개념
- 장고웹
- 사례관리
- 파이썬
- 청소년복지론
- PostgreSQL
- sqlite
- 장고프로젝트
- vue프로젝트
- 자바스크립트for문
- Python
- 개발
- cmd명령어
- 장고웹프로젝트
- javaScriptError
- 오류종류
- forof문
- 자바스크립트수학
- 자바스크립트날짜형식
- Today
- Total
지금도 개발중
R데이터분석 : 데이터 파악하기 본문
1. 데이터를 파악할 때 쓰는 함수들
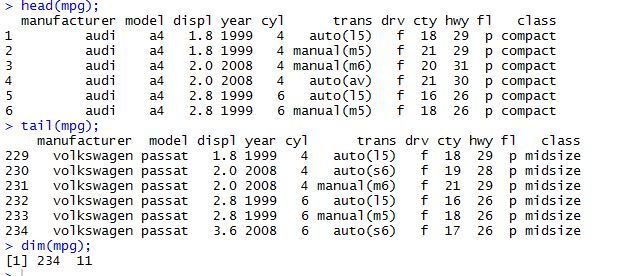
head() : 데이터 앞부분 출력
ex) head(df_exam) - 앞에서부터 6행까지 출력
ex) head(df_exam, 10) - 앞에서부터 10행까지 출력
tail() : 데이터 뒷부분 출력
ex) tail(df_exam) - 뒤에서부터 6행까지 출력
ex) tail(df_exam, 10) - 뒤에서부터 10행까지 출력
View() : 뷰어 창에서 데이터 확인
* 단 view()로 입력하면 Could not find function "view"라고 나온다 꼭 V 대문자

dim() : 데이터 차원 출력
데이터가 몇 행, 몇 열로 구성되어있는지 확인할 수 있는 함수
결과값 : 11 5
str() : 데이터 속성 출력
데이터에 들어 있는 변수들의 속성을 보여준다.

summary() : 요약 통계량 출력

| 출력값 | 통계량 | 설명 |
| Min | 최솟값 | 가장 작은 값 |
| 1st Qu | 1사분위수 | 하위 25% 지점에 위치하는 값 |
| Median | 중앙값 | 중앙에 위치하는 값 |
| Mean | 평균 | 모든 값을 더해 값의 갯수로 나눈 값 |
| 3rd Qu | 3사분위수 | 하위 75% 지점에 위치하는 값 |
| Max | 최대값 | 가장 큰 값 |
# ggplot2의 mpg 데이터를 데이터 프레임 형태로 불러오기
mpg <- as.data.frame(ggplot2::mpg)
* :: 더블 콜론을 이용하면 특정 패키지에 들어 있는 함수나 데이터를 지정할 수 있습니다.


| 변수명 | 내용 |
| manufacturer | 제조 회사 |
| displ | 배기량 |
| cyl | 실린더 개수 |
| drv | 구동 방식 |
| hwy | 고속도로 연비 |
| class | 자동차 종류 |
| model | 자동차 모델명 |
| year | 생산연도 |
| trans | 변속기 종류 |
| cty | 도시 연비 |
| fl | 연료 종류 |
2. 변수명 바꾸기
* 변수명 바꾸는 것은 dplyr 패키지에 있는 rename()을 이용
install.packages("dplyr");
library(dplyr);
# df_new 데이터 프레임의 var1, var2 2개의 변수 중 var2를 v2로 바꾸기
* rename( 데이터 프레임명, 새변수명 = 기존변수명)

** 궁금한 점 : rename()을 사용하면 그대로 해당 상태를 저장(commit)할 줄 알았는데 다시 출력하면 원상태로 돌아와 있음. 왜그런지는 이해가 안감.
3. 파생변수 만들기
1) 합계
df$var_sum <- df$var1 + df$var2;
데이터프레임명$새로운변수명 <- 데이터프레임명$기존변수1 + 데이터프레임명$기존변수2;

2) 평균
df$var_mean <- (df$var1 + df$var2)/2;

3) 조건문함수 - ifelse() *** 중요
ifelse(df$var_sum >= 7, "pass", "fail")
ifelse(조건, true, false)
만약 var_sum의 값이 7이상이면 pass, 그렇지 않으면 fail을 부여하도록 조건문을 만들었습니다.
이 결과값을 result 변수에다가 넣어보도록 하겠습니다.

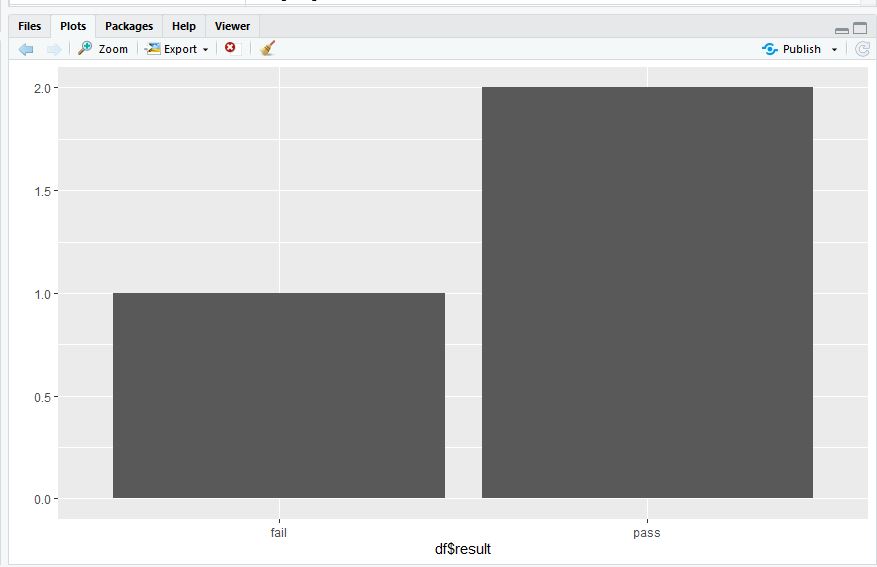
4) 빈도표로 합격 판정 수 살펴보기
table(df$result);

5) 막대 그래프로 빈도 표현하기
library(ggplot2);
qplot(df$result);
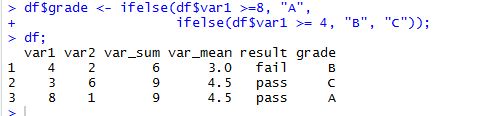
6) 중첩 조건문 *** 중요
아까 전 조건문에서는 pass와 fail 둘 중 하나로 분류하는 변수를 만들었습니다.
이번에는 등급을 매겨서 분류하는 변수를 만들어보도록 하겠습니다.
테이블 프레임 df에 var1 변수가 8이상이면 A, 4~7은 B, 4미만은 C로 분류하겠습니다.

df$grade <- ifelse(df$var1 >=8, "A",
ifelse(df$var1 >= 4, "B", "C"));
'IT > R 데이터분석' 카테고리의 다른 글
| R데이터분석 : 데이터 정제, 이상한 데이터 제거하기 (이상치 정제) (0) | 2019.09.30 |
|---|---|
| R데이터분석 : 데이터 정제, 빠진 데이터 제거하기 (결측치 정제) (0) | 2019.09.23 |
| R데이터분석 : 데이터 가공하기 filter, select, arrange, mutate 등 (0) | 2019.09.17 |
| R데이터분석 : 데이터 프레임 만들기 (0) | 2019.08.29 |
| R 데이터분석 : 변수 만들기 및 사용하기 (0) | 2019.08.27 |



