| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- javaScriptError
- 스택과큐의차이점
- 자바스크립트forinforof차이
- Android
- 개발
- 장고프로젝트
- cmd명령어
- 안드로이드
- 파이썬
- 자바스크립트날짜형식
- 자바스크립트날짜
- 사례관리
- 자바스크립트날짜get
- 청소년복지론
- PostgreSQL
- vue환경세팅
- R데이터분석
- 자바스크립트for문
- 장고
- 장고웹프로젝트
- 오류종류
- 큐개념
- sqlite
- vue환경설정
- vue프로젝트
- 자바스크립트수학
- forof문
- 스택개념
- 장고웹
- Python
- Today
- Total
지금도 개발중
R데이터분석 : 데이터 정제, 이상한 데이터 제거하기 (이상치 정제) 본문
저번 글에서는 데이터 정제 중 빠진데이터 제거하기, 결측치 정제에 대해 배우는 시간이었습니다.
잠시 복습하는 겸 결측치 정제를 다시 확인하고 그 다음 바로 이상한 데이터 제거하기, 이상치 정제에 대해 글을 써보도록하겠습니다.
결측치 정제에 대해 복습
* 결측치 확인 및 출력
is.na(df); //결측치 확인
table(is.na(df)); //결측치 빈도 출력
* is.na()를 filter()에 적용하면 결측치가 있는 행을 제거할 수 있다. 먼저 결측치가 있는 행만 추출한 다음 제거하기!
df %>% filter(is.na(score))
df <- df %>% filter(!is.na(score)) // is.na()앞에 '아니다'를 의미하는 ! 기호를 붙여 !is.na()를 입력하면 NA가 아닌 값을 출력할 수 있다.
* na.omit()은 결측치가 하나라도 있으면 모두 제거하기 때문에 간편한 측면이 있지만, 분석에 필요한 행까지 제거할 수 있다는 단점이 있다.
df_nomiss <- na.omit(df);
* 결측치 제외기능 이용하기
mean(df$score, na.rm = T) //결측치 제외하고 평균 산출
sum(df$score, na.rm = T) //결측치 제외하고 합계 산출
1. 이상치 제거하기 - 존재할 수 없는 값
이상치(Outlier) : 정상 범주에서 크게 벗어난 값.
1) 샘플 데이터 생성하기
성별 변수에는 남자 1, 여자 2로 설정. 점수 변수에는 1~5점을 설정.
하지만 이 설정에서 이상치를 부여. 성별에 3, 점수에 6을 포함시키기.

// 변수에 이상치 데이터가 포함되어 있다는 사실을 알게 되었으니 이상치를 결측치로 변환하겠습니다.
// ifelse()를 이용해 이상치일 경우 NA로 부여
ifelse( 성별 == 3이면 NA, 아니면 기존값 )

// 점수 변수도 성별과 동일하게 5점 이상이면 결측치로 변환하기
ifelse( 점수 > 5이면 NA, 아니면 기존값 )

// 성별, 점수 변수 모두 이상치를 결측치로 변환했으니 분석할 때 결측치를 제외하면 됩니다.
전 글에서 결측치 제외할 때 썼던 filter()를 이용해서 평균을 구하기
* filter()만 이용했을 때의 예시입니다.
temp1 <- outlier outlier %>% filter(!is.na(sex) & !is.na(score)) //저번 썼던 is.na()를 이용해서 결측치 제거
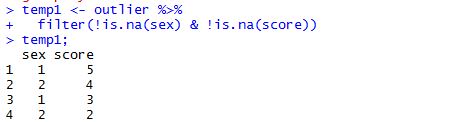
// 그 다음은 결측치를 제외한 후 성별에 따른 score 평균을 구하기

* 여기서 중요! 만약 summarise라는 함수가 안나올 경우, library(dplyr)을 했는지 확인하기!!
R데이터분석 처음할 때부터 강조했던 내용으로, library는 패키지와 달리 항상 해줘야한다.
2. 이상치 제거하기 - 극단적인 값
극단치 : 논리적으로 존재할 수 있지만 극단적으로 크거나 작은값
1) 상자 그림으로 극단치 기준정하기
//mpg 데이터의 hwy 변수로 상자그림을 만들어보기. 상자그림은 boxplot()을 이용하여 지정가능.
boxplot(mpg$hwy);
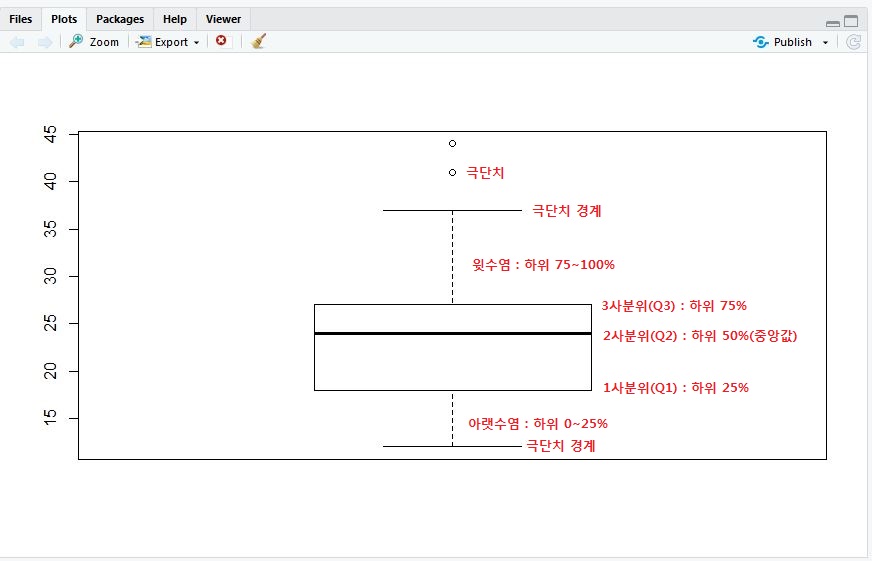
// 결과값을 보면 알 수 있듯이, 하위 25% 지점에 18, 중앙에 24, 75%지점에 27이 위치
2) stats()를 이용하여 다섯 가지 통계치 출력하기
boxplot(mpg$hwy)$stats;
stats() : 상자그림 통계치 출력하는 기능

| 순번 | 통계값 | 상자그림 값 | 설명 |
| 1 | 12 | 아래 극단치 경계 | Q3 밖 1.5 IQR 내 최대값 |
| 2 | 18 | 1사분위수 | 하위 25% 위치 값 |
| 3 | 24 | 중앙값 | 하위 50% 위치 값(중앙값) |
| 4 | 27 | 3사분위수 | 하위 75% 위치 값 |
| 5 | 37 | 위 극단치 경계 | Q1 밖 1.5 IQR 내 최대값 |
3) 결측 처리하기
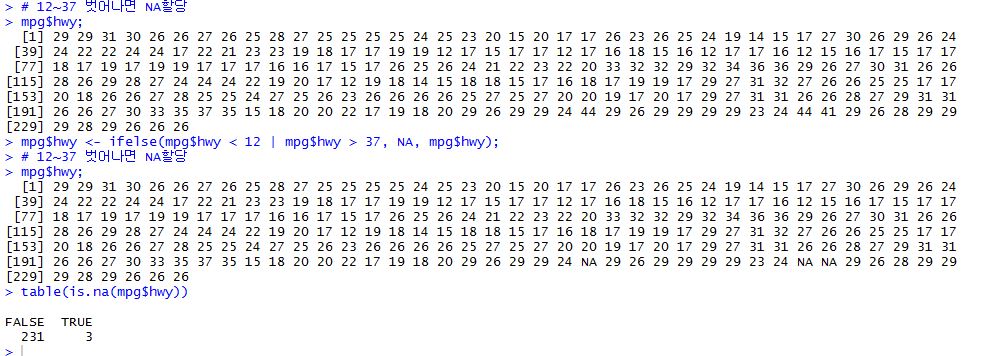
//결측치 제외하고 간단한 분석

3. 혼자서해보기
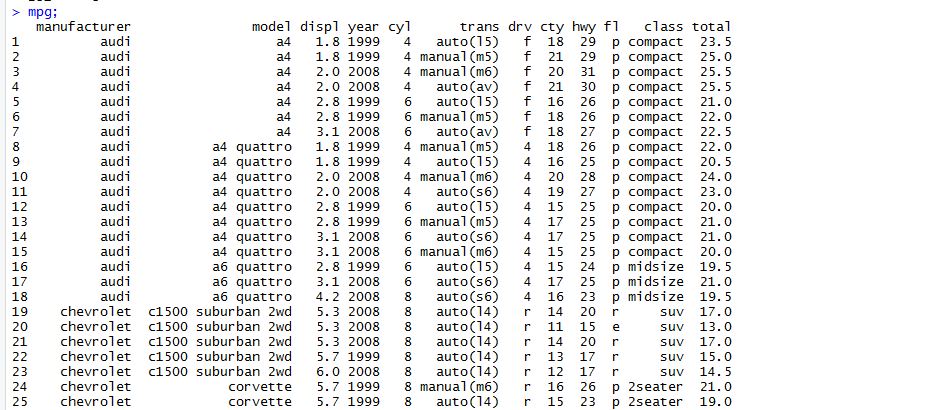
우선 mpg 데이터를 불러와 일부러 이상치를 만들기. drv(구동방식) 변수의 값은 4(사륜구동), f(전륜구동), r(후륜구동) 세종류로 되어있는데 몇 개의 행에 존재할 수 없는 값 k를 할당. cty(도시 연비) 변수도 몇 개의 행에 극단적으로 크거나 작은 값을 할당.
mpg <- as.data.frame(ggplot2::mpg); //데이터불러오기
mpg[c(10,14,58,93), "drv"] <- "k" //drv 이상치 할당
mpg[c(29,43,129,203), "cty"] <- c(3,4,39,42) //cty 이상치 할당
* 코드에서 [] 대괄호는 데이터의 위치를 지칭하는 역할을 합니다. 대괄호 안에서 쉼표 왼쪽은 '행위치', 오른쪽은 '열위치'를 의미합니다.
Q1. drv에 이상치가 있는지 확인 및 이상치를 결측 처리한 후 이상치가 사라졌는지 확인하기.
결측 처리할 때는 %in%기호를 활용하기
mpg$drv <- ifelse(mpg$drv == "k", NA, mpg$drv); // k이면, 결측처리
mpg$drv <- ifelse(mpg$drv %in% c("4", "f", "r"), mpg$drv, NA) // %in%을 이용하여 결측 처리
// 우선 정답지에 있는 내용은 하늘색
Q2. 상자 그림을 이용해 cty에 이상치가 있는지 확인하기. 정상 범위를 벗어난 값을 결측 처리한 후 다시 상자그림으로 이상치 사라졌는지 확인하기.
boxplot(mpg$cty)$stats;

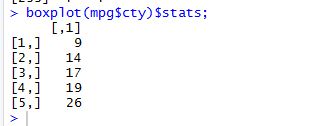
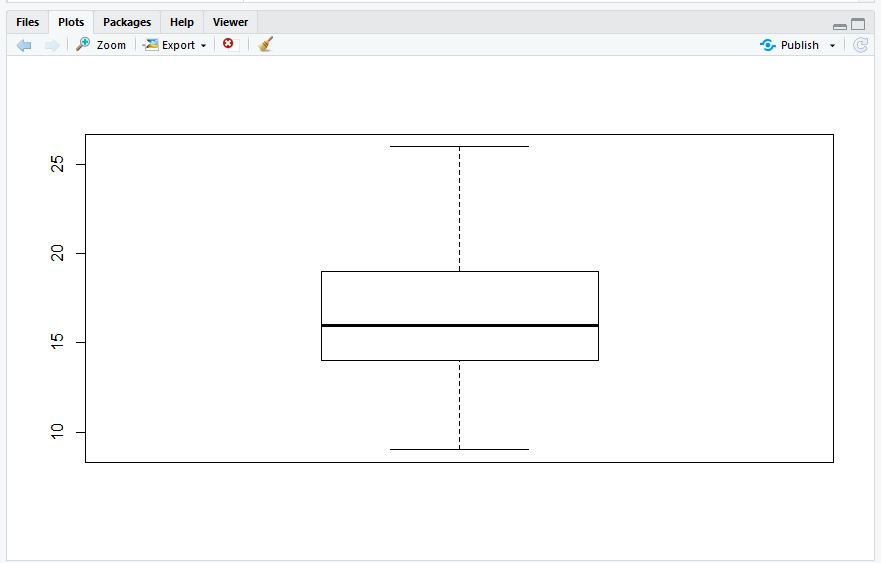
// 9~26을 벗어나면 NA할당(결측 처리)
mpg$cty <- ifelse(mpg$cty < 9 | mpg$cty > 26, NA, mpg$cty);
mpg$cty <- ifelse(mpg$cty >= 9 & mpg$cty <= 26, mpg$cty, NA);
Q3. 두 변수의 이상치를 결측 처리 했으니 이제 분석 차례. 이상치를 제외한 다음 drv별로 cty 평균이 어떻게 다른지 알아보기
1) 이상치를 제외한 다음
mpg %>% filter(!is.na(cty) & !is.na(drv)) %>%
2) drv별로
group_by(drv) %>%
3) cty 평균구하기
summarise(mean_cty = mean(cty))
작성 :
mpg %>% filter(!is.na(cty) & !is.na(drv)) %>%
group_by(drv) %>%
summarise(mean_cty = mean(cty))

** 중요 : ifelse()를 쓸 때에는 mpg$cty로 작성했지만 filter(), group_by() 등과 같은 함수에서는 mpg$cty가 아닌 cty이다.

'IT > R 데이터분석' 카테고리의 다른 글
| R데이터분석 : 그래프 만들기 (0) | 2019.10.01 |
|---|---|
| R데이터분석 : 데이터 정제, 빠진 데이터 제거하기 (결측치 정제) (0) | 2019.09.23 |
| R데이터분석 : 데이터 가공하기 filter, select, arrange, mutate 등 (0) | 2019.09.17 |
| R데이터분석 : 데이터 파악하기 (0) | 2019.09.16 |
| R데이터분석 : 데이터 프레임 만들기 (0) | 2019.08.29 |